
In continuation to Big Data Solutions Decision Tree, it makes sense to provide additional details on Enterprise Information Management (EIM). In this article we will define EIM as solutions making possible optimal use of information within organizations to support decision-making processes or day-to-day operations that require the availability of knowledge.
For this purpose, we will look into following aspects of EIM:
- Master data management (MDM) is a method of enabling an enterprise to link all of its critical data to one file, called a master file, that provides a common point of reference. MDM streamlines data sharing among personnel and departments, and can facilitate computing in multiple system architectures, platforms and applications. MDM is used for quality improvement, to provide the end user community with a “trusted single version of the truth” from which to base decisions.
- Data Cleansing is the process of detecting and correcting (or removing) corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data.
- Extract, Transform, Load (ETL) refers to a process in database usage and especially in data warehousing that performs: data extraction (extracts data from homogeneous or heterogeneous data sources), data transformation (transforms the data for storing it in the proper format or structure for the purposes of querying and analysis), and data loading (loads data into the operational data store, data mart, or data warehouse).
- Metadata management is end-to-end process and governance framework for creating, controlling, enhancing, attributing, defining and managing a metadata schema, model or other structured aggregation system, either independently or within a repository and the associated supporting processes (often to enable the management of content).
- Streaming Data Processing will be covered in a separate post and decision tree.
Here is the decision tree, which maps these areas to specific solutions. Below I will provide some comments on each of them.
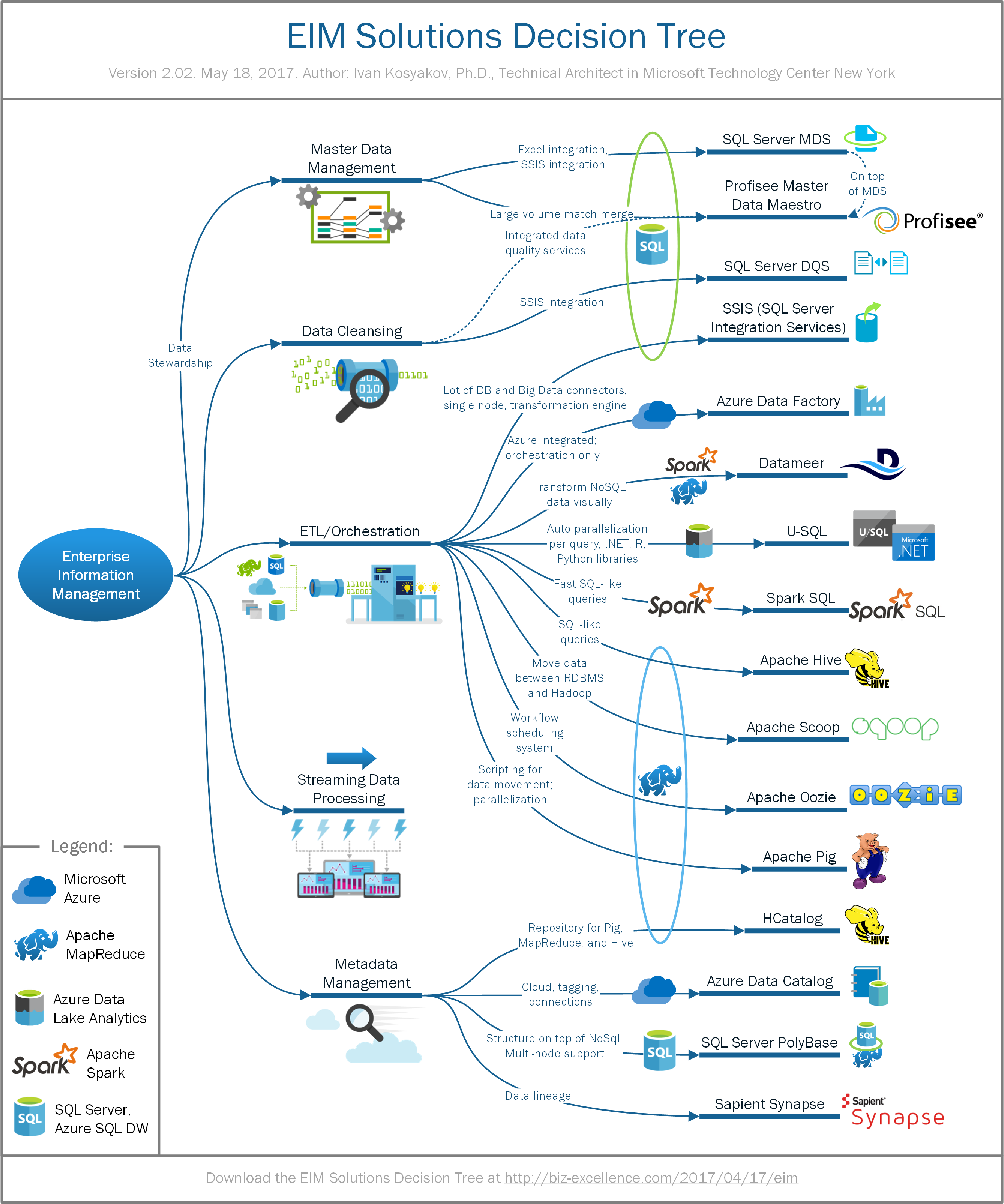
Master data management (MDM):
- SQL Server Master Data Services (MDS) is the SQL Server solution, which can be used by organizations to discover and define non-transactional lists of data, with the goal of compiling maintainable master lists. You can use MDS to manage any subject domain, create hierarchies, define granular security, log transactions, manage data versioning, and create business rules.
- Profisee Master Data Maestro is an enterprise-grade master data management software suite designed to deliver powerful data stewardship and data quality capabilities to customers deploying multi-domain MDM solutions. The Maestro suite delivers a best-in-class user interface to ensure optimal efficiency and productivity for data stewards, innovative large-volume match-merge capabilities for authoritative Golden Record Management, and integrated data quality services to standardize and verify location and contact data across domains. Combined together with Microsoft MDS as a core platform, they provide a world-class out-of-the-box software solution for enterprise-grade master data management applications.
Data Cleansing:
- SQL Server Data Quality Services (DQS) allows data steward or IT professional to create solutions to maintain the quality of their data and ensure that the data is suited for its business usage. DQS enables you to discover, build, and manage knowledge about your data. You can then use that knowledge to perform data cleansing, matching, and profiling. You can also leverage the cloud-based services of reference data providers in a DQS data-quality project.
Extract, Transform, Load (ETL):
- SQL Server Integration Services (SSIS) is a platform for building enterprise-level data integration and data transformations solutions. It includes a rich set of built-in tasks and transformations; tools for constructing packages; and the Integration Services service for running and managing packages.
- Azure Data Factory (ADF) is a cloud-based data integration service that orchestrates and automates movement and transformation of data. Data Factory works across on-premises and cloud data sources and SaaS to ingest, prepare, transform, analyze, and publish data.
- Datameer takes full advantage of the scalability, security and schema-on-read power of Hadoop providing an elegant front end that reinvents the entire user experience, making the previously linear steps of data integration, preparation, analytics and visualization a single, fluid interaction. It provides Smart Execution technology on top of MapReduce, Tez, and Spark, which frees users from having to determine what compute framework is optimal for their various big data analytics jobs by automatically optimizing performance across both small and large data.
- U-SQL is the new big data query language of the Azure Data Lake Analytics service. It combines a familiar SQL-like declarative language with the extensibility and programmability provided by C# types and the C# expression language and big data processing concepts such as “schema on reads”, custom processors and reducers. It also provides the ability to query and combine data from a variety of data sources, including Azure Data Lake Storage, Azure Blob Storage, and Azure SQL DB, Azure SQL Data Warehouse, and SQL Server instances running in Azure VMs.
- Spark SQL is a Spark module for structured data processing. Spark SQL uses information about the structure of both the data and the computation to perform extra optimizations. There are several ways to interact with Spark SQL including SQL and the Dataset API. When computing a result, the same execution engine is used, independent of which API/language you are using to express the computation.
- Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop.
- Apache Sqoop is a command-line interface application for transferring data between relational databases and Hadoop. It supports incremental loads of a single table or a free form SQL query as well as saved jobs which can be run multiple times to import updates made to a database since the last import. Imports can also be used to populate tables in Hive or HBase. Exports can be used to put data from Hadoop into a relational database. Sqoop got the name from sql+hadoop.
- Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
- Apache Oozie is a server-based workflow scheduling system to manage Hadoop jobs. Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions. Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availability. Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts). Oozie is a scalable, reliable and extensible system.
- Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. Structure of Pig programs is amenable to substantial parallelization, which in turns enables them to handle very large data sets. Pig’s infrastructure layer consists of a compiler that produces sequences of Map-Reduce programs, for which large-scale parallel implementations already exist. Pig’s language layer currently consists of a textual language called Pig Latin with properties like ease of programming, optimization opportunities, and extensibility.
Metadata management:
- Azure Data Catalog is an enterprise-wide catalog in Azure that enables self-service discovery of data from any source. Key component of Azure Data Catalog is a metadata repository that allow users to register, enrich, understand, discover, and consume data sources. It uses crowd sourcing model, which means that any member of organization can contribute.
- HCatalog is a table storage management tool for Hadoop that exposes the tabular data of Hive metastore to other Hadoop applications. It enables users with different data processing tools (Pig, MapReduce) to easily write data onto a grid. HCatalog’s table abstraction presents users with a relational view of data in the Hadoop distributed file system (HDFS) and ensures that users need not worry about where or in what format their data is stored — RCFile format, text files, SequenceFiles, or ORC files.
- PolyBase is a technology that accesses and combines both non-relational and relational data, all from within SQL Server.
- Sapient Synapse is a centralized platform that helps organizations efficiently manage and capture data requirements and metadata using a series of highly visual, web-based tools. Key capabilities: information mapping, data requirements management, view transparency and lineage, research metadata, impact assessment, and data mapping across sources.
Additional resources:
