
Azure Cosmos DB is a globally distributed database service designed to elastically and independently scale throughput and storage across any number of geographical regions with a comprehensive SLA. It supports document, key/value, or graph databases leveraging popular APIs and programming models: MongoDB, Graph, SQL, JavaScript, Cassandra, Spark, ETCD and Table.

Azure Cosmos DB provides the best capabilities of relational and non-relational databases: global distribution, horizontal scale of storage and throughput, guaranteed latency limits, high availability, multi-model + SQL + OSS APIs, and comprehensive SLAs.
Characteristics of Azure Cosmos DB and how it can help with relational data storage.
- Azure Cosmos DB has single-digit millisecond response times and guaranteed speed at any scale.
- Applications that are written for Azure Table Storage can migrate to the Azure Cosmos DB Table API with few code changes.
- Azure Cosmos DB Table API and Table Storage share the same table data model and expose the same create, delete, update, and query operations through their SDKs.
<sections in progress…>
Azure Synapse Link for Azure Cosmos DB
Azure Synapse Link for Azure Cosmos DB (NoSQL, MongoDB, Gremlin) enables near real time analytics over operational data in Azure Cosmos DB. Azure Synapse Link creates a seamless integration between Azure Cosmos DB and Azure Synapse Analytics Serverless SQL Pool or Spark Pool.
The following image shows the Azure Synapse Link integration with Azure Cosmos DB and Azure Synapse Analytics:

Azure Cosmos DB analytical store is a column-oriented representation of operational data in Azure Cosmos DB. This analytical store is suitable for fast, cost-effective queries on large operational data sets, without copying data and impacting the performance of your transactional workloads. Analytical store automatically picks up high frequency inserts, updates, deletes in transactional workloads in near real-time, as a fully managed capability (“auto-sync”) of Azure Cosmos DB. No change feed or ETL is required.
Advantages:
- Reduced complexity with No ETL jobs to manage
- Near real-time insights into your operational data
- No impact on operational workloads
- Optimized for large-scale analytics workloads
- Cost effective since eliminates extra storage and compute layers for traditional ETL/analytics
- Analytics for locally available, globally distributed, multi-region writes
Change Feed
The Azure Cosmos DB change feed (NoSQL, MongoDB, Cassandra, Gremlin) enables efficient processing of large datasets with a high volume of writes. Change feed also offers an alternative to querying an entire dataset to identify what has changed. There are following patterns for usage of Change Feed.
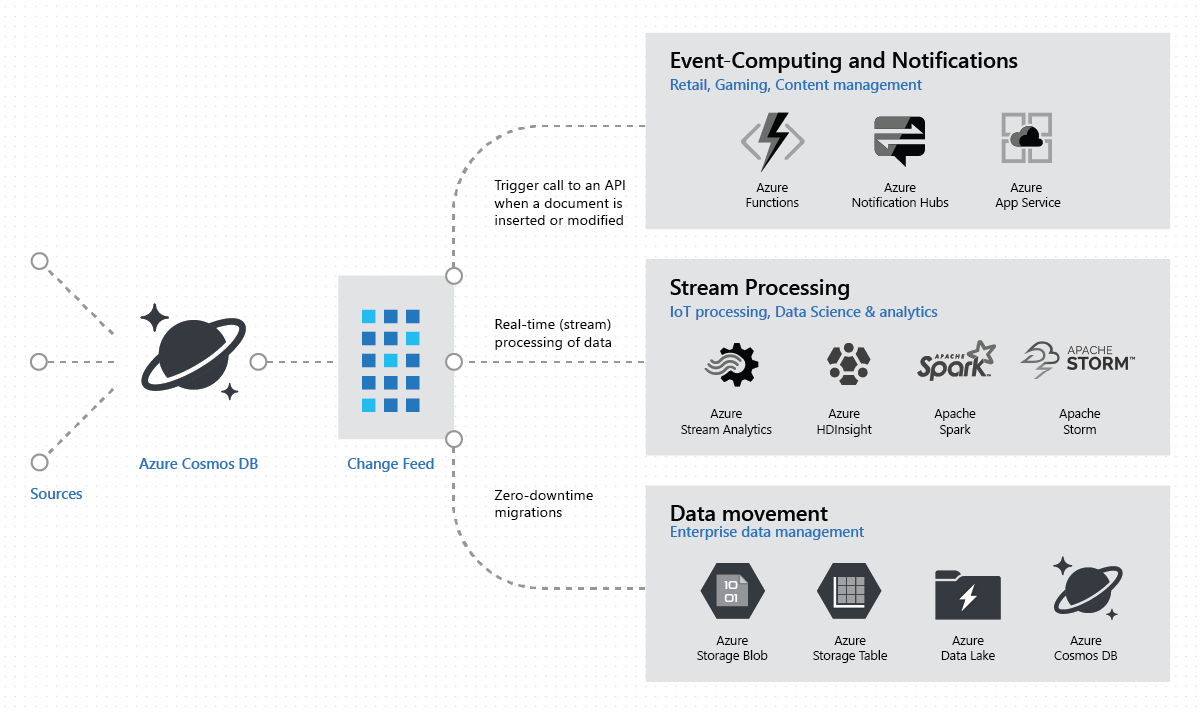
Event Computing and Notifications
The Azure Cosmos DB change feed allows to trigger a notification or send a call to an API based on a certain event.
Real-time Stream Processing
The change feed is able to support a sustained high rate of data ingestion with guaranteed low read and write latency. It’s additional mechanism of reading the data — if you read data from the change feed, it will always be consistent with queries of the same Azure Cosmos DB container.
Data Movement
You can also read from the change feed for real-time data movement such as synchronizing with a cache, a search engine, a data warehouse, or cold storage.
Change Feed Usage
You can work with change feed using the following options:
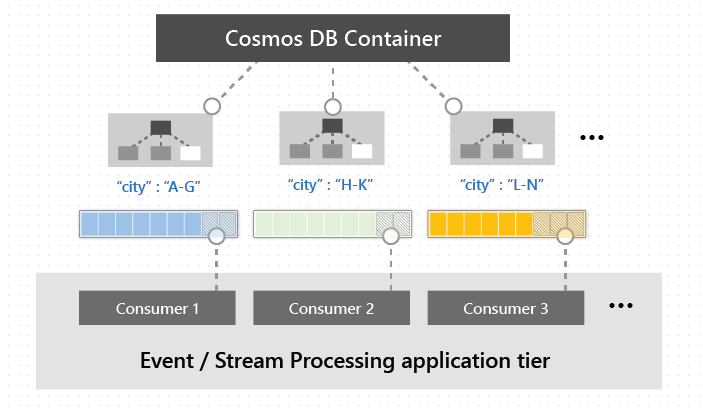
Change feed is available for each logical partition key within the container, and it can be distributed across one or more consumers for parallel processing as shown in the image below.
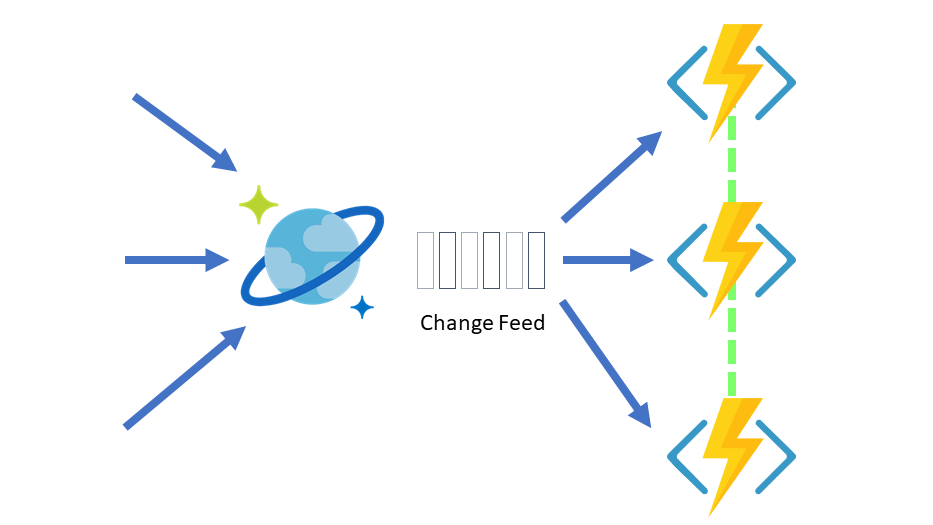
Change Feed with Azure Functions
Azure Functions provides the simplest way to connect to the change feed. Small reactive Azure Functions will be automatically triggered on each new event in your Azure Cosmos DB container’s change feed.
Change feed processor
The change feed processor simplifies the process of reading the change feed and distributes the event processing across multiple consumers effectively.
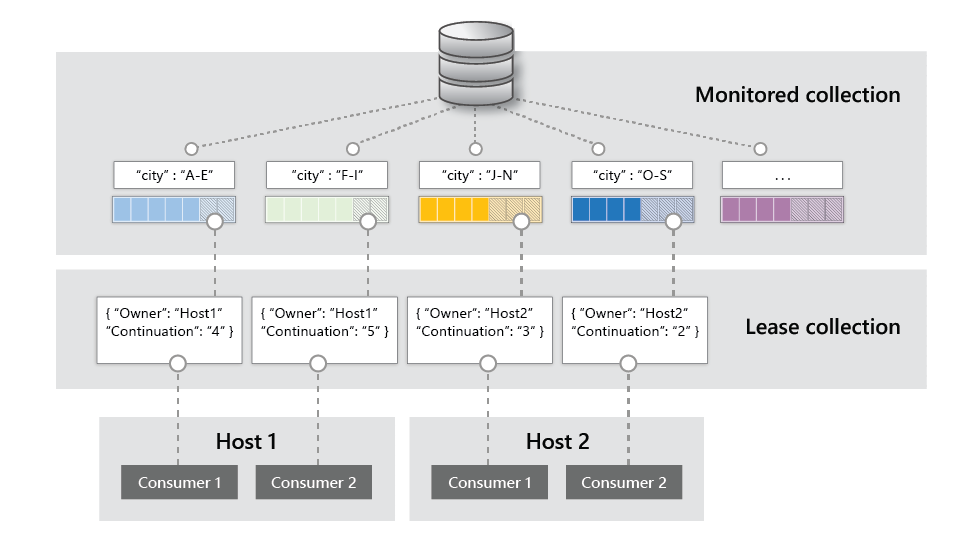
There are four main components of implementing the change feed processor:
The monitored container: The monitored container has the data from which the change feed is generated. Any inserts and updates to the monitored container are reflected in the change feed of the container.
The lease container: The lease container acts as a state storage and coordinates processing the change feed across multiple workers. The lease container can be stored in the same account as the monitored container or in a separate account.
The compute instance: A compute instance hosts the change feed processor to listen for changes. Depending on the platform, it could be represented by a VM, a Kubernetes pod, an Azure App Service instance, an actual physical machine. It has a unique identifier referenced as the instance name.
The delegate: The delegate is the code that defines what you, the developer, want to do with each batch of changes that the change feed processor reads.
The change feed processor can be hosted in any platform that supports long running processes or tasks:
- A continuous running Azure WebJob.
- A process in an Azure Virtual Machine.
- A background job in Azure Kubernetes Service.
- A serverless function in Azure Functions.
- An ASP.NET hosted service.
Another option is to use Azure Databricks which is described by Christopher Tao in his article: Stream Your Cosmos DB Changes To Databricks with Spark 3
Features:
- You can monitor how far the Change Feed Processor lags behind in processing changes in your Azure Cosmos DB container.
Advantages:
- Fault-tolerant behavior that assures an “at-least-once” delivery of all the events in the change feed.
- In most cases when you need to read from the change feed, the simplest option is to use the change feed processor.
Disadvantages:
- Real-time data replication with the change feed can only guarantee eventual consistency.
Change Feed Pull Model
You should consider using the pull model in these scenarios:
- Read changes from a particular partition key
- Control the pace at which your client receives changes for processing
- Perform a one-time read of the existing data in the change feed (for example, to do a data migration)
Advantages:
- Allows to process changes from just a single partition key
Disadvantages:
- More complex compared to Change Feed Processor.
- Unlike when reading using the change feed processor, you must explicitly handle cases where there are no new changes.
Reference materials
- Azure Cosmos DB Official Page
- Documentation:
- Microsoft Virtual Academy: Azure Cosmos DB: Planet-Scale NoSQL
- Microsoft Learn:
- Christopher Tao. Stream Your Cosmos DB Changes To Databricks with Spark 3
