
Last update: 2022
High availability architectures help to keep an application or process running despite unfavorable events and adverse conditions.
Disaster recovery is process of recovering from high-impact events that result in downtime and data loss.
Recovery objectives:
- Recovery Point Objective (RPO) – the maximum duration of acceptable data loss.
- Recovery Time Objective (RTO) – the maximum duration of acceptable downtime.

Recovery plans should include information about:
- Backups: How often they’re created, where they’re located, and how to restore data from them
- Data replicas: The number and locations of replicas, the nature and consistency characteristics of the replicated data, and how to switch over to a different replica
- Deployments: How deployments are executed, how rollbacks occur, and failure scenarios for deployments
- Infrastructure: On-premises and cloud resources, network infrastructure, and hardware inventory
- Dependencies: External services that are used by the application, including SLAs and contact information
- Configuration and notification: Flags or options that can be set to gracefully degrade the application, and services that are used to notify users of application impact.
HA/DR for Azure Services Overview
Azure infrastructure is composed of geographies, regions, and Availability Zones, which limit the blast radius of a failure and therefore limit potential impact to customer applications and data. The Azure Availability Zones construct was developed to provide a software and networking solution to protect against datacenter failures and to provide increased high availability (HA) to Microsoft customers.
Availability Zones are unique physical locations within an Azure region. Each zone is made up of one or more datacenters with independent power, cooling, and networking.
Availability Zones can be used to spread a solution across multiple zones within a region, allowing for an application to continue functioning when one zone fails. With Availability Zones, Azure offers industry best 99.99% Virtual Machine (VM) uptime service-level agreement (SLA). Zone-redundant services replicate your services and data across Availability Zones to protect from single points of failure.

High Availability for Azure VMs
With Availability Zones, Azure offers industry best 99.99% VM uptime SLA. The full Azure SLA explains the guaranteed availability of Azure as a whole. The following diagram illustrates the different levels of HA offered by a single VM, Availability Sets, and Availability Zones.

HA/DR for Data Warehouse (Azure Synapse Dedicated SQL Pool)
Key concepts:
- A data warehouse snapshot creates a restore point which can be used to recover or copy data warehouse to a previous state.
- A data warehouse restore is a new data warehouse that is created from a restore point of an existing or deleted data warehouse.
- Snapshots of a data warehouse are taken throughout the day creating restore points that are available for seven days.
- Additionally up to 42 user-defined restore points can be created manually.
- If geo-backup is enabled, it is created once per day to a paired data center. The RPO for a geo-restore is 24 hours.
Considerations: need to make sure that restore operation will be consistent with Data Lake and sources; will need to re-execute ELT procedures from the point in time.
Reference Materials:
- Backup and restore in Azure Synapse Dedicated SQL pool
- Geo-restore a dedicated SQL pool in Azure Synapse Analytics
HA/DR for Azure Storage
Key concepts:
- Geo-redundant storage (GRS) or geo-zone-redundant storage (GZRS) copies data asynchronously in two geographic regions that are at least hundreds of miles apart. If the primary region suffers an outage, then the secondary region serves as a redundant data source. Initiate a failover to transform the secondary endpoint into the primary endpoint if there is an outage in primary region.
- Read-access geo-redundant storage (RA-GRS) or read-access geo-zone-redundant storage (RA-GZRS) provides geo-redundant storage with the additional benefit of read access to the secondary endpoint. If an outage occurs in the primary endpoint, applications configured for read access to the secondary and designed for high availability can continue to read from the secondary endpoint. Microsoft recommends RA-GZRS for maximum availability and durability for applications.

Reference Materials:
HA/DR for Azure SQL DB and Managed Instance
General Purpose Service Tier
With General Purpose, the primary replica uses locally attached SSD for the tempdb. The data and log files are stored in Azure Premium Storage, which is locally redundant storage (multiple copies in one region). The backup files are then stored in Azure Standard Storage, which is RA-GRS by default. In other words, it’s globally redundant storage (with copies in multiple regions).
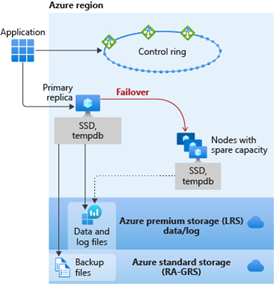
Business Critical Service Tier
Using Business Critical is like deploying an Always On availability group (AG) behind the scenes. The data and log files are all running on direct-attached SSD, which significantly reduces network latency. In this AG, there are three secondary replicas. One of them can be used as a read-only endpoint (at no additional charge). A transaction can complete a commit when at least one of the secondary replicas has hardened the change for its transaction log.

Extended option (for no additional fee) is a zone-redundant configuration if the region supports that. At a high level, the Always On Availability Group (AG) that runs behind Business Critical databases and managed instances is deployed across three Availability Zones within a region. This capability protects against catastrophic failures that might occur to a datacenter in a region.

Hyperscale Service Tier
The Hyperscale service tier is currently available for Azure SQL Database, and not Azure SQL Managed Instance (Dec 2022). This service tier has a unique architecture because it uses a tiered layer of caches and page servers to expand the ability to quickly access database pages without having to access the data file directly.

Active Geo-replication for Azure SQL DB
Active geo-replication is available for Azure SQL Database. You can configure active geo-replication for any database in any elastic database pool. You can use active geo-replication to:
- Create a readable secondary replica in a different region.
- Fail over to a secondary database if your primary database fails or needs to be taken offline.

Auto-failover Groups for Azure SQL Managed Instance
Auto-failover groups should be used for geographic failover of instances of SQL Managed Instance. Auto-failover groups enable replication (and failover) of a group of databases (on a server or all databases in a managed instance) to another region.

Reference Materials for SQL HA/DR:
- Microsoft Learn: Recommend a high availability solution for relational data storage
HA/DR for Azure Data Factory
The ADF service is managed by Microsoft: In all regions (except Brazil South and Southeast Asia), Azure Data Factory data is stored and replicated in the paired region to protect against metadata loss. During regional datacenter failures, Microsoft may initiate a regional failover of your Azure Data Factory instance. When the Microsoft-managed failover has completed, you’ll be able to access your Azure Data Factory in the failover region.
Considerations: If you use Self-hosted Integration Runtime, you need to associate it with multiple on-premises machines or virtual machines in Azure (AKA nodes). Up to four nodes can be associated with a self-hosted integration runtime.
Reference materials:
HA/DR for Azure Databricks
Two alternative approaches:
- Synchronization client that copies from primary to secondary: A sync client pushes production data and assets from the primary region to the secondary region. Typically this runs on a scheduled basis.
- CI/CD tooling for parallel deployment: For production code and assets, use CI/CD tooling that pushes changes to production systems simultaneously to both regions. For example, when pushing code and assets from staging/development to production, a CI/CD system makes it available in both regions at the same time. Most artifacts could be co-deployed to both primary and secondary workspaces, while some artifacts may need to be deployed only after a disaster recovery event.
Reference materials:
Load Balancing for Application Resiliency
Load balancers are essential in keeping your application resilient to individual component failures and to ensure your application is available to process requests. For applications that don’t have service discovery built in, load balancing is required for both availability sets and availability zones.
Load-balancing technology services:
- Azure Traffic Manager provides global DNS load balancing. Can provide load balancing of DNS endpoints within or across Azure regions. Traffic manager will distribute requests to available endpoints and use endpoint monitoring to detect and remove failed endpoints from load.
- Azure Application Gateway provides Layer 7 load-balancing capabilities, such as round-robin distribution of incoming traffic, cookie-based session affinity, URL path-based routing, and the ability to host multiple websites behind a single application gateway. Application Gateway monitors the health of all resources in its back-end pool by default, and automatically removes any resource considered unhealthy from the pool. Application Gateway continues to monitor the unhealthy instances and adds them back to the healthy back-end pool once they become available and respond to health probes.
- Azure Load Balancer is a Layer 4 load balancer. You can configure public and internal load-balanced endpoints and define rules to map inbound connections to back-end pool destinations by using TCP and HTTP health-probing options to manage service availability.
One or a combination of all three Azure load-balancing technologies can ensure you have the necessary options available to architect a highly available solution to route network traffic through your application.

Reference:
- Microsoft Learn: Build a highly available architecture
