
New version is available: Artificial Intelligence Decision Tree
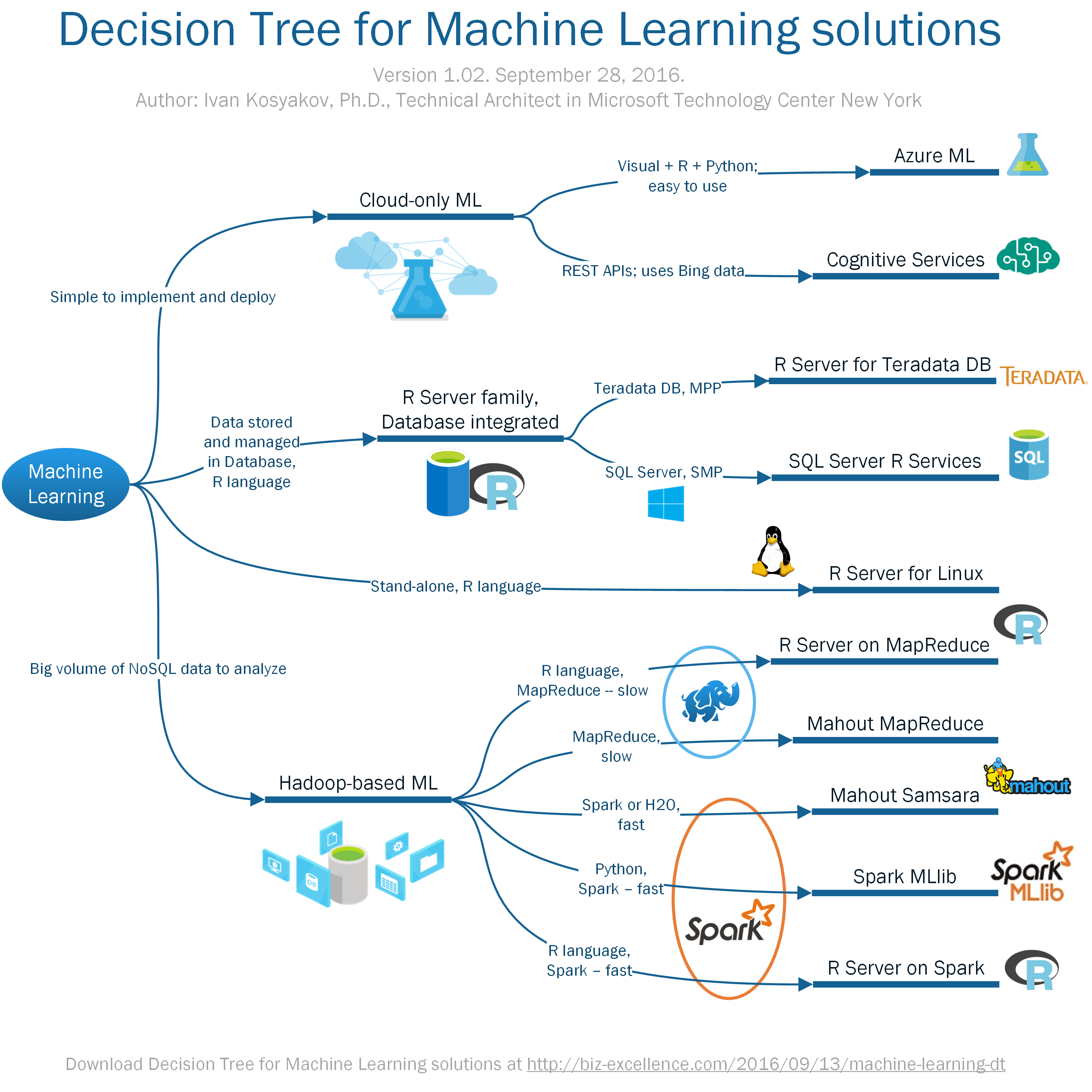
Machine learning is a technique of data science that helps computers learn from existing data in order to forecast future behaviors, outcomes, and trends. Currently there are lot of products which can be used for this on-premises or in the cloud, based on single node or multiple nodes, in relational database or in Hadoop based storage.
This article will help you to choose right Machine Learning solution based on specific requirements. We will discuss open source products, which can be deployed in Microsoft Cloud (Azure), or Microsoft products which can be deployed on-premises.
Disclaimer. In this article I present most important decision points based on my experience. You may use it as first approximation to start looking deep into described and other solutions.
Decision on which product will be selected also depends on development platform used by specialists in organization, and on what Big Data solution is already used or there are plans to use. Key questions here are “Do you already use Hadoop or Data Warehouse?” (SPP or MPP?), “In the cloud or on-premises?”, and “How many data needed for machine learning?” (If storage and ML engine are separated, what will be cost and latency of data transfer?).
Process of machine learning solution selection may influence selection of Big Data solution itself. (Please see decision tree on Big Data solutions in a separate article).
Also, complexity and uniqueness of machine learning problem is important, and how much of effort the team is ready to provide to develop ML solution. Some of product are much easier to use (Azure Machine Learning), and for some tasks there are standard APIs available (Azure Cognitive Services).
Please note that some products can be deployed on top of one platform. (For example, MLlib and R Server deployed on top of Spark cluster).
So let’s see the decision tree first. Below I will provide some comments on each of products. (You may also download high-resolution printable version of the decision tree).

Azure Machine Learning
Azure Machine Learning (ML) is a cloud-based predictive analytics service that makes it possible to quickly create and deploy predictive models as analytics solutions.

In Machine Learning Studio, you can create predictive models by dragging, dropping, and connecting modules. Studio also provides a library of algorithms and samples to get you started. You may create new ML experiment using sample experiments, R and Python packages, standard algorithms (modules), and custom R and Python scripts.
In Cortana Intelligence Gallery, you can try analytics solutions authored by others or contribute your own.
Data Science development: Visual, R language and Python.
Advantages: Graphical experiments representation; easy to study; quick deployment; Excel integration; scalable in terms of multiple experiments.
Concerns: May not be fastest solution to process large amount of data using one single experiment – make sure that all components of your experiment can scale
Cognitive Services
Cognitive Services are a collection of artificial intelligence REST APIs. With Cognitive Services, developers can easily add intelligent features into their applications.

Cognitive Services include:
- Vision: From faces to feelings, allow apps to understand images and video
- Speech: Hear and speak to users by filtering noise, identifying speakers, and understanding intent
- Language: Process text and learn how to recognize what users want
- Knowledge: Tap into rich knowledge amassed from the web, academia, or your own data
- Search: Access billions of web pages, images, videos, and news with the power of Bing APIs
The collection will continuously improve, adding new APIs and updating existing ones.
Development: REST APIs.
Advantages: Quickly to use, platform independent, use some publicly available data from Bing.
Concerns: Can be used only for subset of machine learning tasks.
Microsoft R Server Family
Microsoft R Server is a broadly deployable enterprise-class analytics platform based on R; it is scalable and secure. Supporting a variety of big data statistics, predictive modeling and machine learning capabilities, R Server supports the full range of analytics – exploration, analysis, visualization and modeling. It is compatible with the entire collection of open source algorithms, connectors, visualization tools shared openly via CRAN, Bioconductor and other shared resources like GitHub. At the same time key extensions enable R to tackle big data challenges that exceed the capacity of open source R. Scripts can be developed on the desktop and immediately deployed to RDBMS – SQL Server, EDW (SQL Server & Teradata) or Hadoop (Microsoft, Cloudera, Hortonworks and MapR).

Data Science development: R language (Open R, Scale R).
Advantages: Distributes work across cores and nodes (if multiple nodes available); R Scripts built using R Server can be easily run on multiple platforms running R Server, on-premises and in the cloud (important for hybrid scenarios).
SQL Server R Services (R Server for Windows)
SQL Server R Services (also known as R Server for Windows) is Advanced Analytics and Stand Alone Server Capability built into SQL Server Enterprise Edition. It brings the perfect mix of fast querying and In-Memory OLTP optimization from SQL Server 2016, as well as data exploration, predictive modeling, scoring, and visualization from the R Services family of products. It delivers speed and performance for advanced analytics using near-database analytics and parallel threading and processing. It is integrated with SQL Server: T-SQL can call a Stored Procedure with R code, R scripts can run in SQL through extensibility model, and result sets can be sent through Web API to database or applications.
Data Science development: R language (Open R, Scale R).
Advantages: Included into SQL Server; distributes work across cores; no database data movement, which means it will work much faster; data generated by data scientists using R language can be secured and managed by DBAs and queried by data analysts.
Concerns: Uses only resources of one physical server.

R Server for MapReduce
R Server for MapReduce uses Apache MapReduce nodes for R computations.
Using R Server in MapReduce eliminates data movement latency and removes data duplication if you already use MapReduce for data storage.
Supported platforms: HDInsight Premium, Hortonworks, Cloudera, MapR.
Data Science development: R language (Open R, Scale R)
Advantages: Distributes work across cores and nodes; if you have lot of MapReduce code and have no plans to move off MapReduce, deploying R Server on top of it will eliminate data movement for machine learning.
Concerns: Uses MapReduce which is slower than Spark.
R Server for Spark
R Server for Spark uses Apache Spark nodes for R computations at in-memory speeds using Spark RDDs. R Server for Spark leverages Spark DAG (Directed Acyclic Graph to distribute work across the cluster) and persistence for computation (we may leave the task running and waiting for new requests). In this scenario you can develop models using larger amounts of data with better performance.
Using R Server in Spark eliminates data movement latency and removes data duplication if you already use Spark for data storage.
Supported platforms: HDInsight Premium with Spark and R Server, Spark on Hortonworks, Spark on Cloudera, Spark on MapR.
Data Science development: R language (Open R, Scale R)
Advantages: uses Spark, which means fast in-memory computations; distributes work across cores and nodes.
R Server for Teradata DB
R Server for Teradata DB uses MPP architecture for R computations.
Data Science development: R language (Open R, Scale R)
Advantages: works with Teradata DB; distributes work across cores; no database data movement, which means it will work much faster; data generated by data scientists using R language can be secured and managed by DBAs and queried by data analysts.
R Server for Linux
Data Science development: R language (Open R, Scale R)
Advantages: distributes work across cores.
Concerns: uses only resources of one physical server; additional time will be used to copy or stream data to Linux machine from HDFS.
Mahout MapReduce
Mahout MapReduce is a collection of machine learning algorithms based on Hadoop MapReduce framework.
Platform: Hadoop MapReduce, Java.
Advantages: Mahoot MapReduce comes with many ML algorithms to choose from; MapReduce is much more mature framework then Spark, therefore more stable.
Concerns: Slow and does not handle iterative jobs very well (constrained by disk accesses due to MapReduce).
Mahout Samsara
Mahout Samsara is a Scala-based programming environment based on different distributed engines (Spark and H2O) which also contains machine learning algorithms. It uses all algebraic expressions in R-like Scala DSL which means that is can be readable by R programmers and in general is easier to understand.
Platform: Hadoop Spark, Scala.
Advantages: Fast due to use of Spark.
Concerns: Currently is under development – unstable.
MLlib
MLlib is Spark’s scalable machine learning library consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, as well as underlying optimization primitives.
MLlib ships with Spark as a standard component, so it works seamlessly with SparkSQL, Spark Streaming and Spark GraphX. Additionally, you may deploy R Server on top of Spark cluster.

Platform: Spark.
Data Science language: Python and Scala/Java.
Advantages: due to in-memory capabilities MLlib runs iterative algorithms 5-10 times faster than Mahoot based on Hadoop MapReduce; efficient and interoperable with SparkSQL, Spark Streaming & Spark GraphX; clear and consistent APIs.
Concerns: not all algorithms are implemented, though MLlib is growing very rapidly.
Additional information
- Azure Machine Learning documentation
- MSDN. Microsoft R
- David Chappell. Introducing Azure Machine Learning
- Scalable Collaborative Filtering with Apache Spark MLlib (Compares MLlib and Mahoot MapReduce)

{kind=link}